Roundtable: Amazon Redshift Best Practices for BI, Part 1
Posted by on July 30, 2015 Technology,
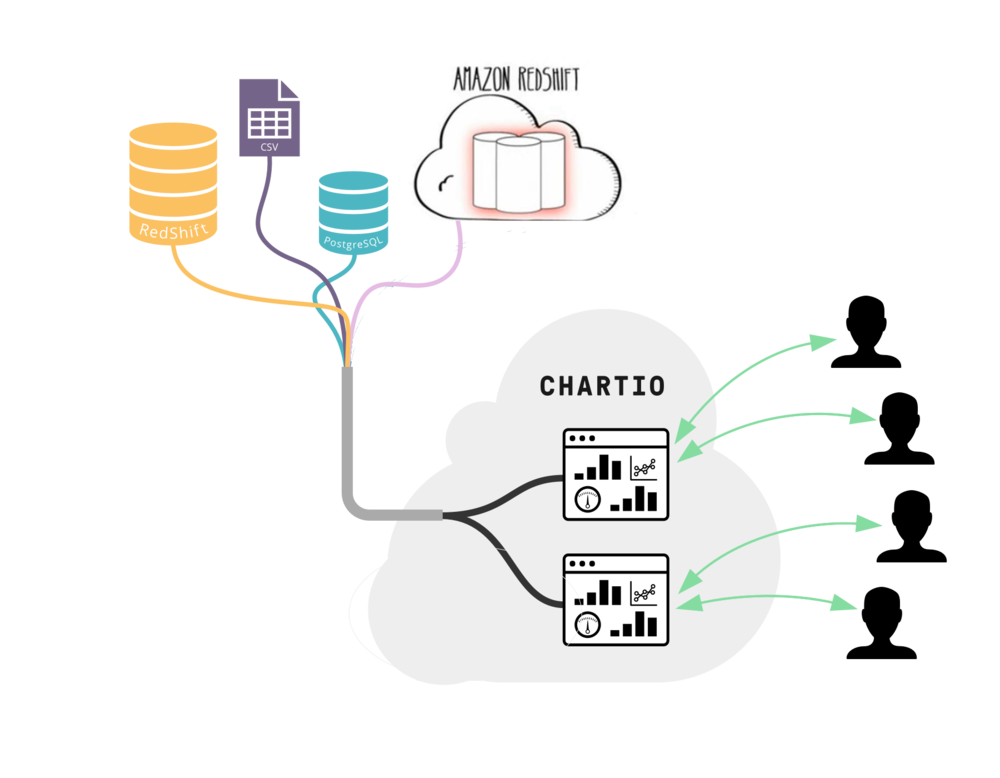
Earlier this month, Chartio hosted a roundtable on best practices for Amazon Redshift. Since many of our customers store their data on Redshift, we wanted to bring together a panel of people with expertise in using Redshift for business intelligence applications. We were able to assemble a great team of panelists:
-
Tina Adams, Product Manager at Amazon Redshift
-
AJ Welch, Data Engineer at Chartio
-
Nathan Leiby, Software Engineer at Clever
-
Marc Bollinger, Engineering Manager of the Analytics Team at Lumosity
We held the roundtable, which was moderated by Jordan Hwang, Chartio’s VP of Growth, at WeWork in SOMA in San Francisco.
Be sure to check out part 2 of this post. If you want more detail, or to see the rest of the discussion right away, we’ve posted the full video of our Amazon Redshift Best Practices in Business Intelligence roundtable.

Tina Adams, AJ Welch, Nathan Leiby, and Marc Bollinger
How do you use Redshift and where does it fit within your data analytics architecture?
AJ: We use Redshift internally at Chartio, but a lot of my experience comes from working with our customers. So that’s what I’ll be talking about today.
Nathan: At Clever we’ve historically stored our application data in Mongo. We use Redshift to store all our newest business analytics and event data and anything we want to access via SQL.
Marc: At Lumosity, we had a pretty robust reporting infrastructure that required a lot of time from data engineers to make everything configurable for the user. Redshift enabled us to flip everything so that data engineers could focus on ETL, infrastructure, and storage and users could leverage SQL as the interface. Everything goes into Redshift from Hadoop EMR jobs to events to application data. We do so much in Redshift, and it has transformed how we work.
What does your ETL process look like?
Nathan: We have two kinds of data that go into Redshift: real-time events and rich data that doesn’t change very frequently, such as details about classrooms and students.
For real-time data, our developers write a log and that log gets centralized. Then, we have a router that forwards that information to Redshift in different ways and writes it to the appropriate tables.
For the data that doesn’t change frequently, we’ve built our system around Mongo and use MoSQL to copy data to Postgres. Then we copy data in batches to Redshift. So, we can join the real-time data with our more static metadata, and get useful information out by using Redshift queries.
Marc: Most of our data is fairly well-structured. For the analyses that we do foresee, we have a more traditional ETL architecture. We have OLTP tables that we roll up to OLAP tables in MySQL and then we roll things up further into Redshift.
But we really use Redshift to analyze things that are not foreseen. We have a fairly sparse table that keeps a rolling window of events that allows us to join to metadata and ask questions like, “Let me see the people who clicked on a particular pixel who have an LPI, which is our performance index, over a certain amount”.
We can do analyses on the fly, typically based on new data. If it becomes something that we do regularly, as a data engineering team, we’ll go back and optimize the ETL process to support this analysis. And we still have the option to use Hadoop, Hive, Spark, etc. Quite frankly, we have a lot more work to do but it’s mostly on the ETL before the data goes in to Redshift.
Can you share any tips around loading and staging data?
Tina: I’ll have to talk in generalities, but many of our customers actually use S3 and then use our COPY command to parallel load into Redshift, and that’s fairly performant. We also have integration between our other services like Elastic MapReduce, which a lot of customers use for ETL, and now you can do a direct copy from Elastic MapReduce into Redshift. Or you can do a similar direct copy from DynamoDB in to Redshift. So there’s a lot of options and you can even work with some of our partners instead of doing it yourself. Staging tends to be dependent on your use case so I’ll let others speak to that.
AJ: I would agree with Tina that it’s definitely dependent on your use case. If you take a look at the Redshift docs, there are plenty of tutorials about the basics like parallelizing your load, using the copy statement, ensuring the number of files being loaded is a multiple of the number of slices that you have, etc.
At a more strategic level, there are techniques that work for different load patterns. Some people batch data into a daily load, others micro-batch and load on more of a real-time basis. One thing that I’ve seen is that, as you move from batch to micro batch, you need to amortize the cost of a few things over some of those micro batches. For example, VACUUM, COMPUPDATE and STATUPDATE usually only need to run after a sizeable amount of activity so you can amortize them over multiple micro-batches. Even something as simple as UPDATE can be amortized, or removed entirely if you have an append-only log. One technique to improve the performance of updates is to have a current table and an archive table and create a view that unions them together. For example, an e-commerce company might have a return window of 60 days. They can safely assume that any orders older than 60 days won’t get updated, and move them to the archive table. That way, the current table, which is the only table we expect to get updated, will be much smaller.
Finally, if you’re loading through S3, keep your raw files on S3 as a backup, so that you can troubleshoot things if anything goes wrong.
Tina: Redshift is a columnar data warehouse. So, the amortizing costs concept you touched on is really a factor of that, as we actually do a lot of work to organize your data into columns.
You’re not going to get a great performance by loading one row. You’ll get an almost similar performance by loading millions of rows with Redshift because it’s designed to be a batch-oriented, analytical data warehouse. But that doesn’t mean that customers can’t do micro batching.
And, while we can do parallel upload and things like that, commits are sequential. We definitely see customers getting into situations where they assume they can commit concurrently from separate transactions because they’re used to OLTP systems. What you want to do is batch you’re commits into a single transaction if possible and you won’t have to worry about your commit queue degrading query performance.
And in terms of slices, Redshift is a clustered data warehouse built on EC2 instances with direct attached storage. Each of those instances has multiple CPUs working at once. If you have a 10 node cluster with 20 slices, you’ll want to have a multiple of twenty files that you’re uploading so each slice can actually do the work. If you only have five files and you have twenty slices, only five of your slices will be doing any work.
That’s kind of important because we see customers saying, “Well, this load is not going nearly as fast as it should.”
“Well, how many files do you have?”
“Oh, two massive files.”
“Well, you’re not really taking advantage of the parallel upload.”
Nathan: We have a pathway that goes from Mongo to Postgres to Redshift, and that’s for the metadata. We needed to sync something like 20 million students across that, and if there are changes, they need to get copied over. That pathway looks like a real-time sync to the Postgres database through MoSQL, and then batch copies over to Redshift.
The main lessons here are write a good tool that’s transactional and does its batch copy in an efficient way, so it’s not interrupting anybody who’s using your warehouse at the time. We’ve built a tool to do that, and we noticed that other people had written similar tools. Feel free to use ours.
End of Part 1
In Part 2, we discuss best practices in schema design, troubleshooting systems with large number of users and tables, and the panelists’ favorite Redshift analyses.
You can also download Chartio’s white paper on optimizing query performance inside your Amazon Redshift cluster to learn more about optimizing queries with common best practices, designing your Amazon Redshift schema and defining query queues in workload management to increase performance and lower costs.