Chartio Meetup: User-Defined Functions in Amazon Redshift
Posted by on November 17, 2015 Chartio
Chartio’s customers are big users of Amazon Redshift as a data source, so we were pleased to host Tina Adams, Senior Product Manager of the Redshift team at our most recent customer meetup. Tina introduced us to user-defined functions in Redshift, reviewed some of their best practices, and took questions from the audience.
If you missed it, you can still view our video of the event.
Amazon introduced scalar UDF’s in September, giving Redshift users the ability upload their own function libraries – or to take advantage of built-in analytic libraries, such as Pandas, NumPy, SciPy for functions such as matrix operations and modeling.
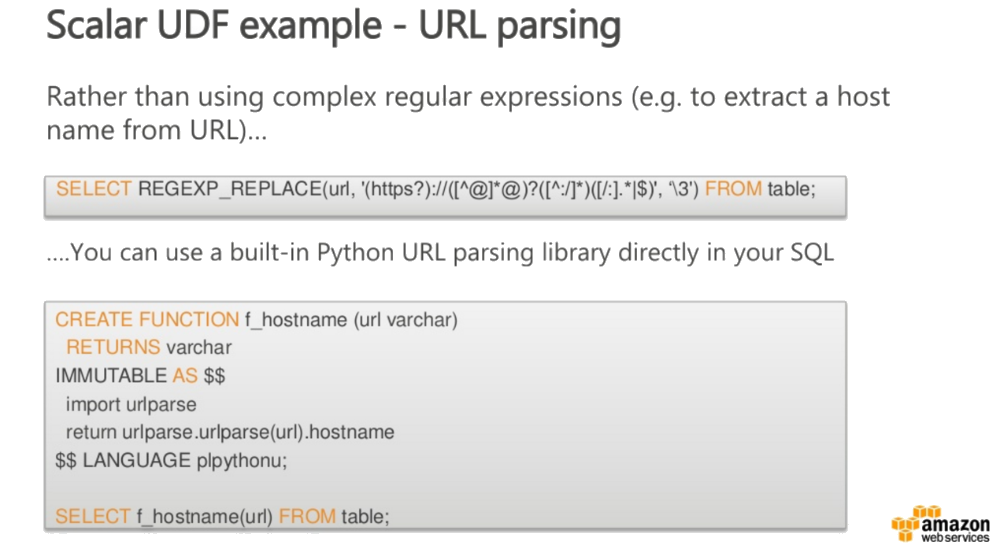
See our video for more slides from this presentation.
Tina noted that the team’s goal in implementing UDF’s was to give users as much flexibility as possible, while maintaining security. For security reasons, UDF’s run in a container that is fully isolated. They cannot make system or network calls, or write files, so they can’t corrupt your cluster.
Tina showed us some example, such as a function for extracting the domain from a URL or calculating the distance between two points based on latitude and longitude.
Chartio’s AJ Welch noted that Chartio users have full access to UDF’s from Chartio’s SQL interface. They can also define a column or table using UDF’s and make that available to non-SQL users of Chartio’s Interactive Mode.
Tina also reviewed a couple of other products, including Kinesis Firehouse, which can load massive amounts of streaming data into Redshift, using your S3 bucket as an intermediate destination.
Check out our video for more information on user defined functions in Amazon Redshift.