Off the Charts: Tony Barbagallo, VP of Marketing at ClustrixDB
Posted by melissa on February 11, 2014 Off The ChartsClustrixDBis an impressive real-time scalable database that’s ideal for analytical uses when paired with Chartio. In the following post we interview Tony Barbagallo, vice president of marketing at Clustrix, about the database. If you happen to be at Strata this week, stop by the Clustrix booth to learn more about Clustrix and see Chartio visualize data across all nodes of the ClustrixDB. If you are a ClustrixDB user and want to connect to Chartio to visualize your data, it is just like connecting to a MySQL database. Follow the MySQL connection instructions within the app.
First off, tell us a little about Clustrix.
Clustrix was founded with the notion that scale-out SQL can provide a business critical platform that is the next-generation system of record that keeps transactional data, reference data, and processed social data delivering massive transaction volume. Our goal is to enable real-time analytics at this intersection of data with the power and simplicity of SQL, so you can do all these things without an army of hard-to-find database engineering talent.
Strata is kicking off today, and we think there will be a lot of conversations about how the cloud has introduced scalable databases and real-time analytics. Tell us how Clustrix plays a part in that.
ClustrixDB was built specifically as a SQL database that can scale seamlessly in the cloud. The cloud has become the perfect medium for flexible performance with the ability to scale performance up seamlessly by adding commodity hardware. ClustrixDB was designed to take maximum advantage of this flexibility. Scaling ClustrixDB as database performance and capacity needs grow is accomplished by simply spinning up a new server and adding it to the cluster. ClustrixDB handles the rest.
Clustrix makes for fast querying on the database. How do you do that?
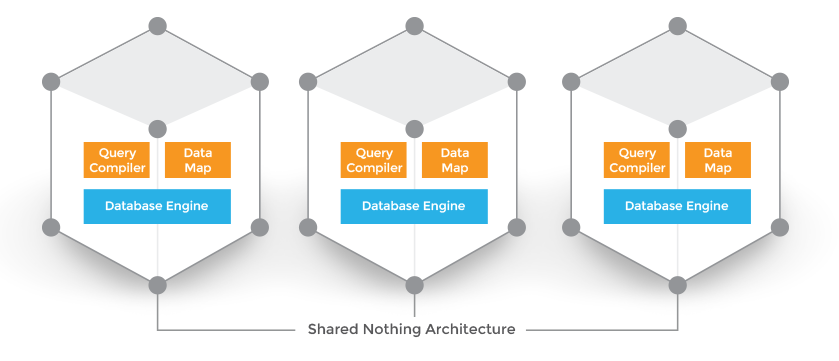
ClustrixDB was designed from the ground up to solve the challenge of scale in the cloud and offer superfast querying of the database. This was accomplished through the precise implementation of a shared-nothing architecture, intelligent data distribution, and distributed query processing. The key characteristic of a shared-nothing architecture is that every node owns part of the data, evenly dividing responsibility for reading and writing to the data and reducing contention. Second, the ClustrixDB Rebalancer ensures that the data and the workload are distributed evenly across the cluster. Given any primary or secondary key, with ClustrixDB slicing every node knows which node owns the data. Lastly, ClustrixDB moves code to where the data is rather than pulling data to the query node. This approach minimizes data movement across the cluster. As the number of queries grows, data motion across the cluster is minimized, allowing ClustrixDB to scale linearly.
How do you compare to other big data relational databases (like Redshift/ ParAccel)?
Relational databases such as Redshift are designed for data warehousing, rather than to be an operational database. These databases are columnar and are focused only on analytics. However, they are not designed to handle transactional workloads that include heavy reads, writes and updates. Every row in a columnar database has to be broken into columns and stored in multiple places and updates are very slow.
ClustrixDB on the other hand, is a relational database that operates on row-based data. It can support massive transaction volumes. In addition, it has massively parallel processing associated with columnar warehouses, that allows ClustrixDB to run significantly faster real-time analytics allowing the user to get real-time insights into the latest operational data.
For a while all anyone talked about was Hadoop, but there seems to be a resurgence of SQL and relational databases. Do you agree and why is that?
Yes, SQL is back in vogue. Application developers that have been using proprietary NoSQL interfaces are beginning to understand the tradeoffs in production environments. They’re coming to appreciate the ease of SQL and the ACID guarantees that come with it. In operational databases, data warehousing and everything in between, vendors are now implementing SQL. CQL for Cassandra, SQL on Hadoop and the recent SumAll move to use a SQL layer on top of MongoDB to get better analytics, are all part of this shift in the industry.
SQL is back in vogue. Application developers that have been using proprietary NoSQL interfaces are beginning to understand the tradeoffs in production environments.
What are other trends you are seeing with companies and their databases?
Real-time analytics are becoming increasingly important because capturing transactions and analyzing them in the same data-management performance tier produces the fastest possible response. This has led to the latest trend toward using in-memory databases. However, for most applications, less than 20 percent of the data is hot and accessed very frequently. The rest of the data is cold and accessed less frequently or rarely, if ever. In-memory databases insist on putting all data into memory which is not cost-effective for most applications.
In-memory databases insist on putting all data into memory which is not cost-effective for most applications.
Clustrix is taking a different approach with ClustrixDB, whereby the hot data is stored in RAM and the remainder on SSDs or spinning disks. The smart combination of memory and SSDs for real-time analytics achieves the highest performance while significantly reducing overall hardware costs. For instance, two terabytes of RAM on AWS for $28 per hour costs approximately $245,000 a year, whereas that same storage capacity using SSDs costs just $1.6 per hour or approximately $14,000 annually.
Related Content
-

Startups, Data and Fundraising - an Interview with Amanda Kattan
Amanda Kattan data and finance consultant -

Data for Good with Aziz Alghunaim, Co-founder and CTO of Tarjimly
Aziz Alghunaim Co-founder and CTO Tarjimly -

An Interview with Daniel Mill of The New York Times
Daniel Mill Director of Marketing Analytics The New York Times