Off the Charts: An Interview with Lukas Biewald of CrowdFlower
Posted by tina on September 26, 2017 Off The Charts
In this edition of Off the Charts, an interview series where we chat with individuals doing industry-changing work in the data space, we spoke with Lukas Biewald— a co-Founder of CrowdFlower. CrowdFlower is the essential human-in-the-loop AI platform for data science teams which helps them generate high-quality customized training data for their machine learning initiatives.
Prior to CrowdFlower, Lukas worked at Powerset, a natural language search technology company that was acquired by Microsoft. Lukas has an MS in Computer Science and a BS in Mathematics from Stanford University. To catch up on the latest from Lukas, read his blog.
Lukas Biewald in his robotics lab.
Can you tell us more about the importance of training data in relation to AI?
People sometimes don’t think about training data as cool or important, but it is. When building an algorithm, you’re essentially taking training data and creating an algorithm based on what it sees from the data.
For example, if you want to build an AI tool to recognize cats and dogs, you’d collect and show it pictures of cats and dogs, as opposed to giving it tools or programming it. Then, as you collect and show it more training data, it really impacts the algorithm.
Algorithms need to see a lot more examples than humans, which makes AI work a lot less powerful than the human brain. But, algorithms can look at more examples than a human. So in domains where there are tons of training data that would be boring for a human to look at, but an algorithm can do amazing things with it.
Do you have an example of where an algorithm consumed more and more data and it was extremely beneficial to the end product?
I think one of the most amazing instances was when Google came out with their translation algorithm. It wasn’t perfect, and it still isn’t today, but when it first came out—it was much better than anything else.
And the reason why was because Google crawled the entire web in one language and translated it into another language.
Before this, the only thing that was available was one large corpus that was published by the European Union. This corpus was all government records published in the different languages that make up the EU. So probably not the best source for translating daily conversation.
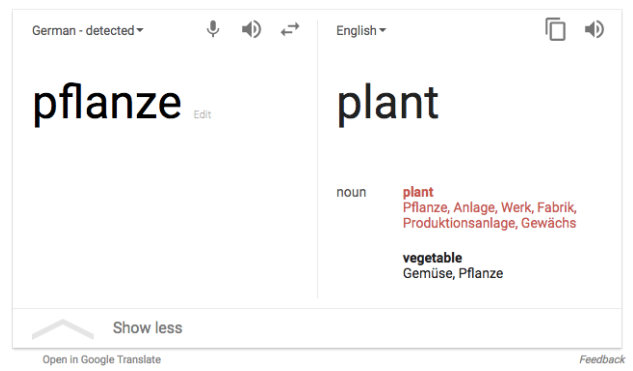
The many translations of pflanze, or plant in German.
For example, in German, plant is ‘pflanze’ and factory is ‘fabrik,’ so every time the word ‘pflanze’ came up, the algorithm would translate the word to factory, which in government makes sense, but it’s not the right meaning for every use case. But there was no way that the algorithm could learn that without different examples that aren’t government records.
It sounds like there was a supply and demand issue. Was research limited by the available data?
Yes, ten years ago, I started CrowdFlower with training data specifically in mind to help fix this issue. At that time, most of the AI research was based on where researchers had specific data sets already available to them.
Now, we have greater access to data and we can do things like build self-driving cars. The work being done around self-driving cars is amazing. Tesla has been able to collect millions and millions of rows of vision data and put all of it into an algorithm for the self-driving car. The data shows where’s the road, sky, etc. It’s impressive.

A still from Tesla’s Self-Driving Demonstration video in 2016.
What are some of the most interesting datasets you’ve worked on over the years?
In the early days of CrowdFlower, Chris (co-Founder) and I, we were discussing which photo to put on our website, and the debate was around which photo made us look most trustworthy. We eventually created a website (FaceStat.com) to settle things, and asked people: how trustworthy do we look?
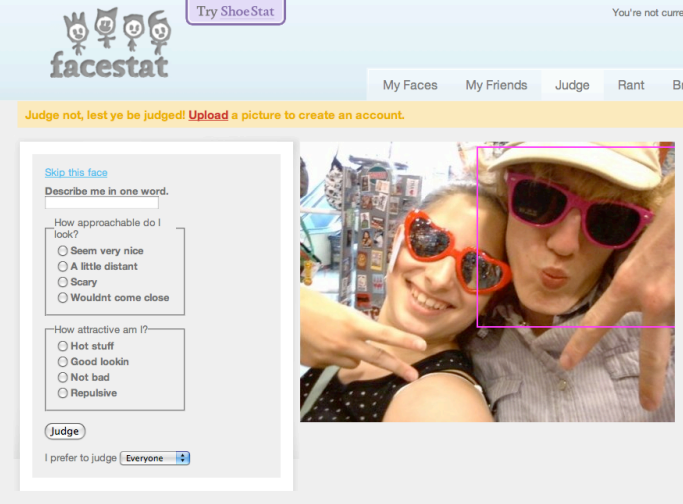
Screenshot of the FaceStat.com interface. (Source: Superficial Data Analysis - Exploring Millions of Social Stereotypes)
Quickly enough, all of our friends wanted to upload their photo and get the same feedback. So, we let our friends upload their photo if they would help us with labelling on CrowdFlower. Then the site took off. All of a sudden we had all this data with millions of images. Some people uploaded thousands of images of themselves.
As the site got more popular, we kept adding more and more questions to the site and we got an incredibly rich dataset. We learned that people are endlessly interested about themselves.
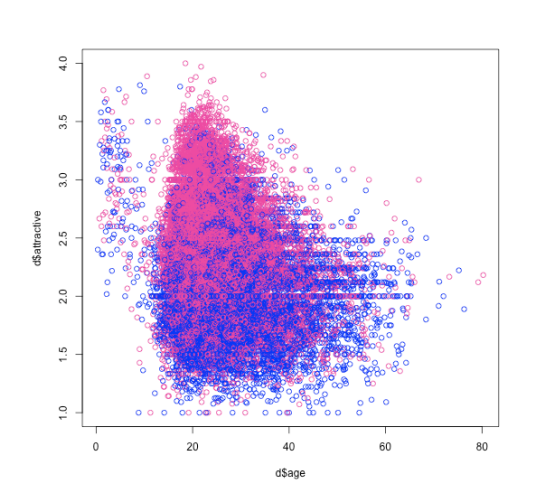
A Scatterplot chart of attractiveness versus age, colored by gender. Data from FaceStat.com. (Source: Superficial Data Analysis - Exploring Millions of Social Stereotypes)
You’ve been working in AI and data for over ten years, how have you seen the industry evolve over the years?
Years ago, I was on the R email list and most of the people on the list were statisticians. One time, I mentioned that I wanted to put a small record set, maybe a million, in-memory and everyone on the email list thought it was a preposterous idea. They even asked me if I heard of sampling. They couldn’t believe that I wanted to load a million records in-memory.
Back then, to visualize something, you only needed so much data. If you wanted to make a simple graph with a dataset, all you had to do was sample the data. But, also, if you wanted to zoom in on a piece of it, you still needed a substantial amount of data.
Today, with machine learning and modeling, we want and need gigantic datasets, but at the time no one saw the point. That feels so quaint now. It’s really interesting how things change.
Related Content
-

Startups, Data and Fundraising - an Interview with Amanda Kattan
Amanda Kattan data and finance consultant -

Data for Good with Aziz Alghunaim, Co-founder and CTO of Tarjimly
Aziz Alghunaim Co-founder and CTO Tarjimly -

An Interview with Daniel Mill of The New York Times
Daniel Mill Director of Marketing Analytics The New York Times