Big data refers to the massive volume of structured and unstructured data that is so large, it is difficult to process using traditional database and software techniques. Using big data, companies can know radically more about their businesses, and directly translate that knowledge into improved decision making and performance.
For example, physical bookstores (brick and mortar stores) can track which books are selling well and which aren’t. Also, if they have a membership program, they can link the purchases to individual customers. However, once shopping moved online, the e-commerce retailers started collecting much more information about purchases and customer behavior.
Apart from the books sold, data is collected on what web pages the customers browsed, how they navigated through the site, and how much they were influenced by layouts, promotions, and reviews. Using this enormous amount of data, algorithms can be written to predict what book the customer might want to read next which, in turn, will improve the overall customer experience. Collecting and analyzing big data is a major driver for the success of businesses.
Features of Big Data
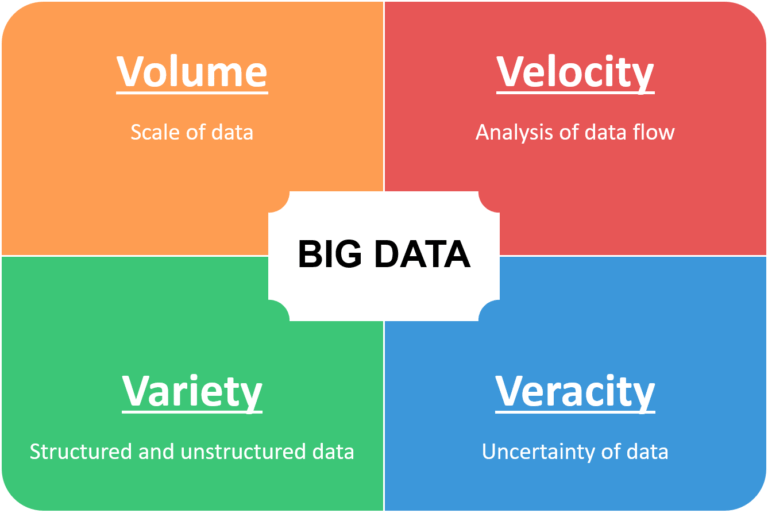
Big Data has four key characteristics which help us understand the advantages, as well as the challenges, faced in big data initiatives. These characteristics are also known as the 4 V’s of Big Data.
- Volume – Volume is the V most frequently associated with big data – data quantity can be so big it can reach incomprehensible proportions. For example, Facebook stores more than 250 billion images uploaded by people, in addition to all the individual posts (over 2.5 trillion posts). Overall, close to 2.5 exabytes (1 Exabyte = 10^9 Gigabytes) of data is being produced every day. And, the total data in the world is expected reach 44 zettabytes (1 Zettabyte = 10^12 Gigabytes) by 2020.
- Velocity – Velocity is the measure of how fast the data is being generated and collected. For example, in Facebook, more than 350 million photos are being uploaded every day. This data needs to be collected, stored, filed, and available to be retrieved whenever required. Data velocity highlights the need to process the data quickly, and most importantly, use it at a faster rate than ever before. Many types of data have a limited shelf-life and their value can diminish very quickly. For example, to improve sales in a retail business, out of stock products should be identified within minutes rather than days or weeks.
- Variety – Data can come in all forms – photos, videos, sensor data, tweets, encrypted packets and so on. Data is not always accumulated in the form of rows and columns in a database – it can either be structured or unstructured. With an increase in data sources, there are more varieties of data in different formats-from traditional documents and databases, to semi-structured and unstructured data including click streams, GPS location data, and social media apps. Different data formats mean it’s tougher to derive value from the data because it must all be extracted for processing in different ways.
- Veracity – Data veracity is the degree to which data is accurate, precise, and trusted. It refers to the biases, noise, and abnormality in the data. To avoid ‘dirty data’ accumulating in our systems, we need to have a strategy to keep the data usable. Having diverse and messy data requires a lot of cleanups. Obtaining and cleaning datasets still takes more time for a data scientist than putting their investigational skills (statistics, machine learning, and algorithms) to use.
Conclusion
Datasets are growing rapidly because they are being captured by cheap and numerous gadgets such as mobile devices, remote sensing, software logs, cameras, microphones, and wireless sensor networks. The work to analyze big data may require massively parallel software running on hundreds or even thousands of servers.
Harnessing the power of big data will enable analysts, researchers, and business owners to make better and faster decisions using data that was previously inaccessible or unusable.
Resources
- Forbes – What is Big Data?
- Harvard Magazine – Why “Big Data” is a Big Deal
- Dataconomy – The Four Essential V’s for a Big Data Analytics Platform