The data pipeline is the set of processes that take your data from one or more raw data sources all the way through to well-organized data that generates insights. The most important steps of a data pipeline come in its initial steps. Data sources must be identified and accessed, and data drawn from these sources. Useful information must be distilled from this data, and stored in a place that users can draw insights. Failure to obtain a complete data picture through any of these steps could cause a company to make poor judgments and be misled.
Two main types of procedures have been developed for the handling of data in this stage of the data pipeline: ETL and ELT. In each procedure, the “E” stands for Extract, “T” for Transform, and “L” for Load, but the order of steps differs between the two. Through this article, you will know how to interpret these two approaches to data processing and why each step is important.
ETL: The Old Standard
The original process for generating analytics-ready data is ETL, originally popularized in the 1970s and refined in the years since. ETL was developed as a systematic method for processing data, to accommodate limitations of computing power. While the need for writing custom code to carry out a pipeline has gradually begun to give way to ETL tools that improve and automate pipeline processes, ETL still remains a standard workflow for ensuring that a company gets the data they need in order to make data-driven decisions.
In the Extract step of the ETL process, connections to data sources are performed and data is extracted. These might be event- or transaction-logging databases, or they might be flat file types like CSV. If data comes from platforms like Salesforce or Stripe, an ETL tool can be useful for setting up proper connections to these data sources. Just make sure that the tool can actually connect to the data sources that your company uses when selecting an ETL application.
In the Transform step, data is cleaned and aggregated. The transformation step is the largest part of the ETL process, since it determines what data will be available for analysis once it is placed in a central data store for users to access. Many operations can be performed here. On the cleaning side of things, this can include filtering out irrelevant data fields, or re-encoding values into standard forms (e.g. setting a consistent date and time format). Aggregation operations can include gathering data points by time period (e.g. counting hourly events). ETL tools can show their power in this step through their understanding of various data sources and data types. They can automate transformations and send out alerts in case of unexpected events.
Finally, in the Load step, the data is saved into a target data store, such as a database or data warehouse. Part of the transformation process is about formatting the data in just try right way that the target data store can handle it. Just as certain ETL tools are capable of drawing from multiple data sources, each ETL tool may be able to integrate with multiple data stores, making the loading step smooth and reliable.
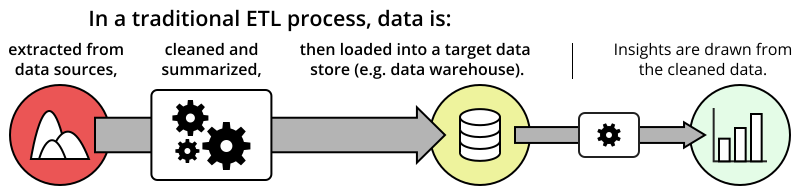
There are other considerations to make when setting up an ETL process. Traditionally, extracted data is set up in a separate staging area for transformation operations. This is a private area that users cannot access, set aside so that the intermediate data can be worked with without affecting the central store. This is a good protection in case issues are found with the data. This also allows for the steps of the ETL process to be performed in parallel. While one batch is being extracted from a data source, the previous batch can be transformed, and the one previous being loaded into the central data store. One point to keep in mind with timing your operations is to make sure that resources are being used at good times: you don’t want to be consuming your data store’s resources with loading new data at the same time most of your users will want to be accessing the data store!
Criticisms of ETL
Simply because the ETL process has a well-established history does not mean that it is without its faults. One issue with ETL is that it can take some time for raw data to make its way into the central data store for use. As the number of data sources and data use cases increase, so too does the delay between data generation and availability. One challenge of ETL tools as well as data storage methods is to minimize that lag time and bring the process as close to real-time as possible.
One other consequence of the steps of an ETL process lies in the separation between a user and the data. Since the only data available to a user is the cleaned and transformed data output from the ETL process, if they find that they need to dig deeper or need to compute additional statistics, then they will need to implement additional processing procedures. This is further exacerbated if the user is different from the maintainer of the ETL process. In order to generate the new measurements, the user needs to contact an engineer or administrator, who then needs to take time to add the measurement to the summaries to be computed by the ETL process. In addition, the new statistic needs time to be computed from scratch, rather than just updated like existing measurements.
ELT: A New Way of Data Processing
With new advances in technology come new problems and new ways of dealing with them. Increases in the number of data sources and the rich potential for insights they contain also increase the demands on data processing systems. Scheduling operations in an ETL process becomes gradually more difficult. However, alongside the increased challenge of handling more data, so too have there been improvements in storage and manipulation of data to match this demand. This has brought about ELT as an alternative approach for handling data at the top of a data pipeline.
While the Extract step of an ELT process covers the same ground as in ETL, there is a major divergence in how the data is handled next. With Load coming after Extract, the raw data, or essentially so, is copied into the data store. There may be some minor data processing steps taken at this point, but they will be limited to simple cleaning operations to ensure that the data is in a form suitable to be added to the data store. The key point is that, in an ELT process, there will not be any aggregation performed before the initial load of the data into the storage. Compare this to an ETL process, where aggregation and summarization operations are also performed to put the data into an analyzable form when it is placed in the data store.
In ELT, the burden of the Transformation step is now placed on the data store. This would not have been a reasonable request until the 2010s, when new developments in data storage systems allowed for fast and efficient analytic queries. The fact that this is now possible is a major driver towards making the ELT approach feasible. Some applications may only be responsible for extraction and loading (EL), and have little management on the transformation side of data processing.
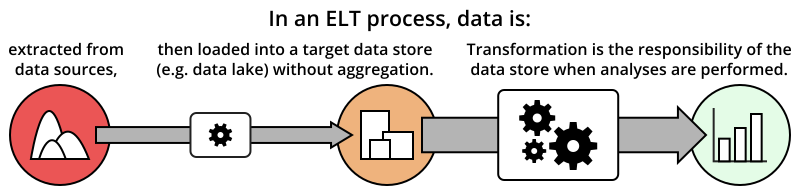
How does Loading first change things?
It is reasonable to ask at this point how ELT is different from just pushing back access to the data one step up the pipeline. First, collecting the data in a central repository makes it easier to combine the data from multiple original data sources. Rather than needing to communicate with multiple data sources and figure out a staging area for intermediate results like in ETL, an ELT procedure can create a more consistent and convenient way of combining data from those sources.
Secondly, the way that data is stored in the original data stores is likely not to be conducive to analytic queries where data needs to be transformed and aggregated. Moving that into a data store that is specialized to performing analytic queries will make working with the data much faster and efficient.
Third, if users are comfortable with the language of a data store with summarized data (e.g. SQL), then they can also use that language with the raw or lightly-transformed data as well. If a user does find something that the ‘usual’ planned summaries doesn’t cover, then they have the freedom to write up a custom query to obtain the summaries they need on their own.
Cautions for ELT
Of course, immediately loading the data into the central data store has its own share of issues. One of these issues is with usability. Increasing the accessibility to more data is a double-edged sword, as it also means that there will be more work to do in order to obtain actionable results. With an EL-fed data store, there will be more data to sift through compared to ETL-fed data stores; which may include needing to generate basic summaries each time they’re needed. Even if intermediate results are transformed and also placed in the data store, they need to be clearly separated from the raw data they were generated from or risk being lost within the rest of the data. Increase in work is not just on the end of the data store, but also on the part of the user. The queries that a user needs to put together may be very complex, depending on how long the path is from raw data to the desired measurement.
A second concern to be aware of is that of data privacy. Since there is a much lighter processing of data before they get to the data store in ELT, you need to be aware of who has access to any personally identifiable information. If there are privacy regulations that need to be observed, then a plan for managing sensitive information also needs to be available.
Another point to be aware of with ELT is that, since the transformations are performed with the data store, there may be limitations in the types of operations that can be performed. While having the data up front might allow a user to create their own transformations without the need of a data expert, there will still be cases where a complex query or limitations of the transformation language will require a data scientist or engineer to step in to assist.
Combined Methods and Modern ETL
What you have seen above is that ETL and ELT not only have differences between each other for how data is collected and processed, but also that within each category, there are multiple ways of thinking about and handling data. One potential way of handling data is to perform multiple stages of processing, combining ETL and ELT and taking the advantages of each. This hybrid approach sometimes goes under the acronym ETLT.
As an example of a hybrid approach, light transformations similar to ELT are applied to the data as it is copied from data sources into a data store. From there, the data goes through an ETL process so that it is summarized in a form that users can more easily perform analyses. This data can be stored in a separate storage area from the lightly transformed data. Now, users have two different places where they can gain insights: one with summarized data built for expected analytic queries, and one with a broader granular data to address questions that aren’t fully covered by the summarized data store.
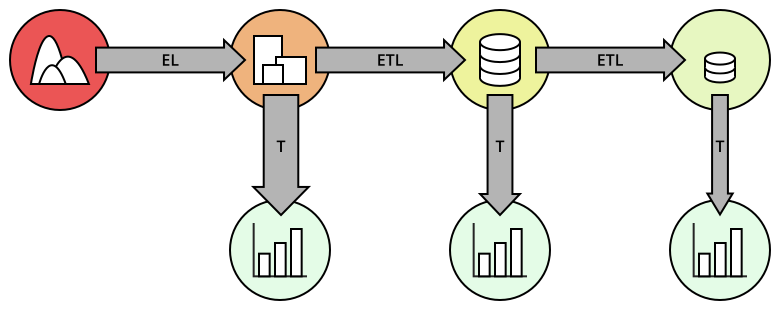 Multiple stages of ELT and ETL can prepare data for different users.
Multiple stages of ELT and ETL can prepare data for different users.
One other trend to be aware of is the fact that ETL and ELT processes are starting to converge with changes in technology. As mentioned in this Stitch article, rather than utilize a staging area for transformations, some modern ETL processes look rather more like ELT, with data transformations actually being performed in the final data store. ETL as a process isn’t completely obsolete, however: transformations that cannot be performed by a data store must be completed using some kind of ETL procedure, whether extracting from a raw data source or from a central data store.
Still, with the advent of online, cloud-based solutions for data handling and storage, there has been less need for a company to keep dedicated in-house resources to writing custom ETL code and storing their own data. Gone are the days of needing to carefully summarize and aggregate loads of files into limited on-site analytic data space. Instead, the main questions to ask when setting up a data pipeline are to consider which tools provide the features and functionality that best fit the needs of a company and the other parts of their data stack.