Big Data Meets the Hype Cycle
Posted by on January 9, 2012 Data, Opinion, Data Governance
Big Data is all the rage these days, judging from the press, analyst reports and the endless webinars in my spam folder. Just as with every other mega-trend in technology, the hype is partly justified and partly not.
What is Big Data?
Sprawling amounts of data are being generated across quite a range of sources and media: financial transactions, weather data, health data, social data, sensor data, mobile data, geo-location data, search data, and the list goes on.
Some of this data, particularly the unstructured kind, is not very suited to traditional tools, mainly, the relational database. But as certain companies explore tools designed for this kind of data structure and volume, something of an echo chamber intermingled with hype has taken over the conversation, much in the same way that NoSQL was all the rage a few years back. The hype even made way for parody.
In the case of NoSQL, the ecosystem eventually realized that databases that don’t conform to strict relational models have their place in certain contexts. But time revealed the hoopla to be a good deal of hype.
The Hype
The fact that data growth is immense is undeniable. But most businesses, practically speaking, do not contend with what is truly Big Data with a capital B & D. As it happens, in 2011, Gartner added Big Data to its notorious “Hype Cycle,” alongside other flavors of the year: Internet of Things, Consumerization and everyone’s favorite, Gamification.
The chart below describes the various phases of the hype cycle, which are segmented into 5 major sections.
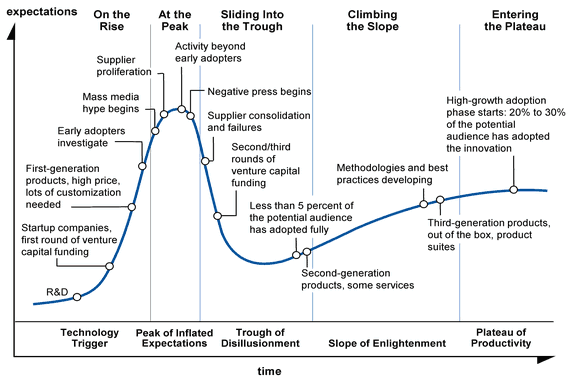
-
Technology Trigger: A tech breakthrough gets the ball rolling. Commercial viability is uncertain.
-
Peak of Inflated Expectations: Early publicity and a few success stories create buzz. Most implementations do not succeed, however.
-
Trough of Disillusionment: Interest wanes as experiments and implementations fail to deliver. Lots of companies fail.
-
Slope of Enlightenment: 2nd and 3rd generation versions start to emerge and bigger companies start to fund pilots.
-
Plateau of Productivity: Mainstream adoption starts to take off. The technology’s broad market applicability and relevance are clearly paying off.
In this chart, Gartner situates “Big Data” on the steep climb up to peak hysteria, as the early adopters began uptake and the mass media (or Big Media, as it were) starts to froth.
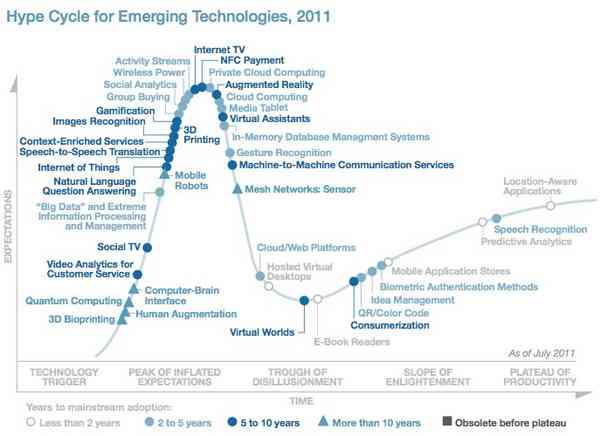
The truth is, most businesses don’t have big data. They have mostly average data. And what might be mistaken for “Big Data” is often really just datasets that are larger than yesteryear, but are still workable with today’s tools.
According to an interview Forbes magazine conducted with Rasmus Wegener, a partner in Bain’s IT practice:
“Instances of Big Data are relatively rare and most Big Data is simply Large Data. And Large Data can be handled with traditional tools.”
To separate Big Ol’ Data from its more modest kin, large data, Wegener suggests four questions:
-
Do you have a significant amount of data that needs to be analyzed? “Typically they say yes, and then we ask if it all has to be analyzed at the same time.”
-
How complex are the analyses you have to run, the number of computing operations required to transform the data into actionable insights?
-
Critical issue — what’s the speed at which the data must be captured and the solution generated? “This is almost always a knockout criterion. When you walk through the airport and they take pictures of everybody in the security line to match every face through facial recognition, they have to do that almost in real-time. That becomes a big data problem. If I am a bank and looking at a vast number of credit scores and histories, and I don’t need to provide an answer in five seconds but can do it next day, then that is not a big data problem.”
-
Degree of structure of the data. Does it contain a significant amount of unstructured data from video or audio, or can it be put into a relational database easily?
All this isn’t to say that massive amounts of data don’t exist and aren’t being generated, processed and analyzed by business. It’s just at the moment, truly big data is mostly manifest in certain industries, including telecommunications firms, internet giants like Google and Facebook, some research firms, certain government organizations and utilities running smart grids.
What will likely emerge from all this noise is a recognition that, yes, certain data volume, speed and structure requirements are better suited to new data technologies. That said, these tools fit certain and limited use cases for the time being and act mostly as a complement to existing data-warehousing deployments. For example, Ebay has retained its Teradata data warehouse for traditional transactional and customer data, but has also adopted Hadoop for clickstream, user behavior and other semi-structured data investigations.
But we should do what we can to clear the fog of hype from our discussions of data. The whole point of storing data is to make sense of it, by leveraging structured data. So relational databases are more than here to stay. And platforms for processing unstructured or semi-structured datasets certainly have a long way to go. That said, we’re hopeful the hype will give way to quality products that make everyone’s data more understandable, using a variety of complementary technologies.