With our customers relying on over 100,000 dashboards and 2,000,000 charts in Chartio to run their business, query performance is something our engineering team is very serious about.
When Chartio issues a remote query, we store the result of it in our remote cache so that we minimize the number of queries that we make against your database. Earlier this year, we finished the cache coordination project which reduces the number of duplicate queries that a user dashboard might end up issuing.
When, as a Chartio user, you visit a dashboard and the data is out of date (was fetched prior to the dashboard’s cache duration), Chartio finds all of the charts that need to be refreshed and issues all the queries with their datasets against your database. However, if a dashboard contained a number of charts that had datasets with the exact same query, Chartio would end up issuing a lot of the same query to the database. This could easily happen for instance if you ended up cloning a chart and then making some changes to the overall chart settings, like using the same dataset to populate a pie chart and a table chart.
The performance impact of duplicate queries was brought up by one of our customers who had a dashboard with a number of charts that had identical queries, but who applied a different filter when transforming the data from each query in the Data Pipeline phase. The customer wanted a setup so that Chartio would only issue one query to their database for the data, so we did an analysis and quickly realized that smarter query execution could have a big impact on the number of queries we could save for all customers.
Queries cause extra load on a customer’s servers while services like Google BigQuery will charge users for running a query based on their overall volume, so reducing the number of duplicate queries that we were performing in Chartio would be a good improvement.
Chartio issues its queries to an Elastic Load Balancer on Amazon Web Services, so a request to build all the charts on a dashboard will end up with these requests handled by a number of different servers. In order to avoid making a duplicate query, we needed some way that our servers could communicate with each other at the start of the query process. After doing some research, we decided to use a distributed locking solution by implementing the distlock algorithm, which uses the Redis database.
When Chartio gets a query request, for each dataset in a chart we have a unique cache key which is formed as a hash of the SQL query that’s being run and a unique identifier for the dashboard. Because of this, if two identical queries are run as the result of a dashboard load, even if they’re used in different charts, they will have the same cache key.
Given this cache key, we run the following procedure before issuing a remote query:
-
Is there a lock in Redis for this cache key already?
-
If no, acquire the lock and issue the query.
- Once the query has succeeded, write its results into the remote cache.
-
If a lock already exists, wait for the lock to be released.
-
Once the lock has been released, check the remote cache for the results and return them. (Skips a query to the database.)
-
If we wait for a certain period of time (currently configured at 30 seconds) and the lock is never available, issue the query.
-
Here’s an example of the code we’re using to run this (Java):
public class CacheCoordinator {
// Configuration values:
// Time lock lives in Redis before expiring
private final long CACHE_LOCK_TIMEOUT_MS;
// Time to attempt to acquire lock before giving up and issuing the query
private final long CACHE_ACQUIRE_LOCK_TIMEOUT_MS;
public CacheLock acquireLock(String cacheKey) {
final String redisKey = getLockingKey(cacheKey);
long startTime = System.currentTimeMillis();
int attemptCount = 0;
try {
while (System.currentTimeMillis() - startTime < CACHE_ACQUIRE_LOCK_TIMEOUT_MS) {
try (Jedis jedis = jedisProvider.get()) {
String randomValue = String.valueOf(random.nextLong());
// https://redis.io/commands/set
// NX - only if key does not exist. PX is milliseconds
String result = jedis.set(redisKey, randomValue, "NX", "PX", CACHE_LOCK_TIMEOUT_MS);
if (result != null && result.equals("OK")) {
return new CacheLock(redisKey, randomValue, attemptCount, Duration.ofMillis(System.currentTimeMillis() - startTime));
}
}
++attemptCount;
Thread.sleep(LOCK_SLEEP_ATTEMPT_MS);
}
} catch (InterruptedException e) {
// Fall through
}
return null;
}
public boolean releaseLock(CacheLock cacheLock) {
if (cacheLock == null) {
// Nothing to do !
return true;
}
try (Jedis jedis = jedisProvider.get()) {
String lockValue = jedis.get(cacheLock.getKey());
if (lockValue != null && lockValue.equals(cacheLock.getValue())) {
LOGGER.info("Successfully released lock: " + cacheLock.getValue());
jedis.del(cacheLock.getKey());
return true;
}
if (lockValue == null) {
LOGGER.warn("Failed to get lock status: " + cacheLock.getValue());
return false;
}
LOGGER.warn(String.format("Lock did not match value (indicates expired lock) value=%s expected=%s", lockValue, cacheLock.getValue()));
return false;
}
}
}
protected QueryResult runQueryWithCache(String cacheKey) throws DataFetchException {
CacheLock lock = this.cacheCoordinator.acquireLock(cacheKey);
// If the lock is non-null, no other queries for this cache key will be performed.
try {
Cache.Result cacheResult = null;
// Check to see if data is in the cache.
try (Cache cache = cacheProvider.get()) {
cacheResult = cache.get(cacheKey);
}
if (cacheResult != null) {
cacheCoordinator.releaseLock(lock);
LOGGER.info(String.format("Query was found in cache - key %s", cacheKey));
return new QueryResult(new CacheDataset(cacheKey, cacheResult), cacheResult.getUpdatedAt(), cacheResult.getExpiresAt());
}
LOGGER.info(String.format("Query was not found in cache - key %s", cacheKey));
QueryResult queryResult = this.runQueryAgainstDatabase();
try (Cache cache = cacheProvider.get()) {
LOGGER.info(String.format("Writing result to cache - key %s", cacheKey));
cache.set(cacheKey, queryResult);
}
return queryResult;
} finally {
// Release the lock so other processes can check the cache
cacheCoordinator.releaseLock(lock);
}
}
In the CacheCoordinator class, we’re using Java 7’s try-with-resources syntax to manage our how our code interacts with the Redis client. We use Guice to manage our dependencies and the JedisProvider is a wrapper around our Jedis library so we can unit test our classes without actually sending requests to a Redis instance. The CacheLock class is a POJO (Plain-Old-Java-Object) that encapsulates some important information about the lock - the random value that was chosen and the number of attempts it took to acquire it (useful for our internal metrics).
In the runQueryWithCache method, we’re first acquiring the lock and then checking the cache. If the data exists in the cache we immediately return it - otherwise we run the query, then write the data to the cache. Afterwards we release the lock. If we fail to acquire the lock we end up going through the same logic, only with a null lock object.
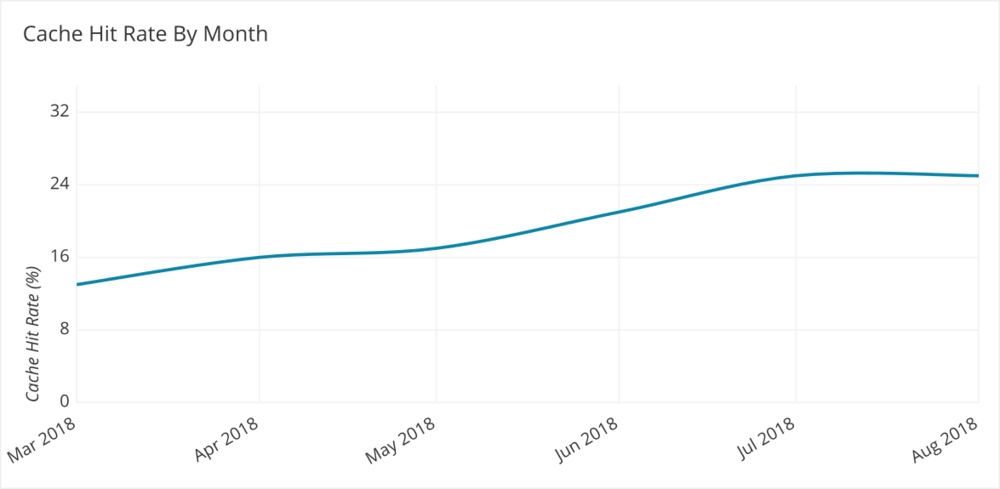
We deployed the cache coordination code near the end of Q2 2018. After deployment, we observed our remote cache hit rate jumped by 57% - from 14% of all queries resulting in a hit to 22% of all queries resulting in a hit. Of our duplicate queries, 90% of them end up reading the result from remote cache, rather than issuing a duplicate query against a customer’s database. Today our overall remote cache hit rate is above 30% in part due to the work we’ve done to reduce our duplicate queries.
Takeaways:
-
Using datasets with the same query reduces the number of queries that Chartio issues against a datasource.
-
Since duplicate queries will wait for the other to complete before running, it’s best if you keep your dashboard queries as fast as possible. If you find yourself with a very large query that feeds into multiple charts, you should investigate using Chartio data stores.