Up Your Database: MADlib + PostgreSQL Extension Ecosystem
Posted by on March 28, 2016 Data Governance
I recently spoke at the community meetup for the MADlib Apache incubator project, an open source library for scalable in-database analytics. Thank you again to the MADlib community for inviting me to speak and for all the great work they contribute to such a cool piece of software!
If you’ve never heard of MADlib and you use PostgreSQL, Greenplum or HAWQ (also an Apache incubator project) then you should definitely check it out. It’s a database extension that allows you to perform advanced statistical and machine learning computations within your database where your data resides. In short, MADlib allows you to leverage the investments you’ve made in your existing database as well as its computational power instead of having to sample or extract data into an external system such as Python, R or Spark.
MADlib gets to the heart of something I’ve written about on this blog before. Too many folks are unfamiliar with just how much relational databases can do these days and they fail to get the full ROI on the investments they’ve made. Part of this is due to a lingering perception that relational databases are only good at descriptive statistics (count, sum, avg, etc.) on medium sized structured data sets. In other words, SQL just doesn’t work for inferential, predictive or causal analysis on larger or unstructured data sets. Although this may have been true five years ago, it’s a lot less true today.
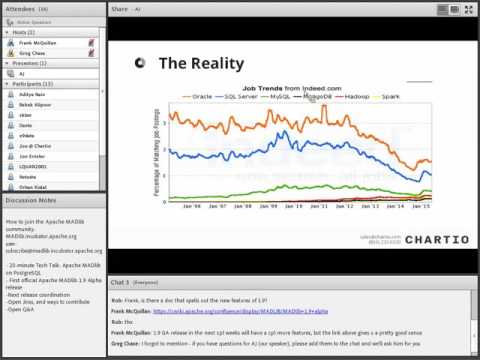
In this talk, I try to illustrate some of the advanced statistical computations that can be done in PostgreSQL using the pg_similarity extension along with MADlib. It’s a reworking of a couple of talks I gave at the Rich Data Summit and PGConf Silivon Valley. I hope it provides some good food for thought and gets you thinking about interesting ways to apply these extensions in your organization.