Good Data Hygiene — Data Lakes, Warehouses and Hygiene
Posted by on August 3, 2017 Data, Data Analytics, Database, Data Governance
Data hygiene is just like personal hygiene; everybody wants it, but not everyone has the easiest time building or maintaining it.
Here we’ll discuss the importance of good data hygiene and highlight key methodologies that will help you build and maintain it. However, before we get into that, let’s review the different ways that you can store your data, as this will have a huge impact on your data organization and your future data hygiene.
First Thing’s First: Data Lakes vs Data Warehouses
In today’s world of big data, there are two common ways to store data - data lakes and data warehouses. While these are different, they are not necessarily mutually exclusive and many organizations build a data architecture that includes both types of storage. Why? There are important advantages and disadvantages to both, especially when it comes to data storage, analytics and hygiene.
Data Lakes: Not Hygienic
Data lakes are easy to setup. The user simply connects the sources to the destination (data lake) and turns on the data flow. There is no need to manage schemas, data types, field names, etc., because data lakes are designed to receive all the data without regard for the specifics of how it should be stored. They are built on inexpensive commodity hardware - often in blob storage like S3, HDFS, or SFTP servers - and the data is generally compressed.
Because of this structure, data lakes will usually hold all data points from the beginning of time when the metric first started being recorded. Additionally, one can store all fields and, since there is no schema enforced, the way that the fields are stored is irrelevant.
Because of this freedom, data lakes are a great place to dump your data.
At this point, it might sound like data lakes are a great solution to support your data analytics pipeline. However, the important thing to keep in mind is that data lakes are not built for analytics. Since there is no schema, no set relationships between data sets and no common pattern for data types and field names, data is difficult to query in a data lake. Additionally, because data lakes tend to be built on inexpensive commodity hardware with compressed data sets, analytic processing built on data lakes is slow. Overall, it just doesn’t work.
Data Warehouses: The Place for Good Data Hygiene
Data warehouses, on the other hand, are built for analytics. In general, data in a data warehouse is very well-organized, with:
-
Well-defined schemas
-
A data architecture to define how tables relate to each other
-
Common data types for specific fields
-
Well-named fields
-
And more
Additionally, data warehouses tend to be built on expensive hardware in sophisticated databases designed for fast queries. Specifically, data warehouses like Amazon Redshift and Google BigQuery are perfect examples of optimal cloud data warehouses that respond with lightning fast analytics - and there are other options out there, too.
That said, there are some disadvantages to data warehouses as well. Because they are built on expensive hardware, users must maintain good data architecture in order to keep costs down. That means that an architect will have to make big decisions about which data points are stored and how it should be organized in order to keep costs down and avoid storing irrelevant data.
This kind of planning and designing will take time up-front, which is why many find it easier to just dump their data somewhere and take a closer look once it has arrived in the destination. That being said, I believe that good data hygiene is always the right solution for building strong analytic insights.
Data Hygiene
What is Data Hygiene?
Good data hygiene is essentially what you see in a well-organized data warehouse. In this scenario, I like to imagine myself wearing a white glove, running my finger along any surface inside the warehouse and seeing no dust collected on my finger. All the tables and relationships are well-ordered and organized, with common patterns for names and datatypes that make sense in relation to each other.
That being said, this is difficult to achieve and it is important to point out that not all data warehouses have this kind of good data hygiene. I’ve worked with many customers who are embarrassed to show me their database schema because the tables are so disorganized. Sometimes we log in through their database console and I see hundreds of tables, many with names suffixed with “_v2”,”_v3”, etc. In these cases, it is clear that there was never a good data architecture put in place.
In such instances, these database administrators are looking for some serious help! Specifically, they’re looking to build powerful analytics with a visualization tool. However, before they do that, they need to get their data organized.
Steps to Maintaining Good Data Hygiene
So how does one build and maintain good data hygiene? Here are the steps:
1. Design a strong data architecture
As we have discussed, it starts with designing a strong data architecture. I like to think of this design process as the “fun part” of ETL or data integration. The stakeholders who know their data sets and are asking for the ability to run analytics will already have a strong sense of what data they want to collect. Of course, there will always be data points that users don’t know they want - that’s the whole point of building analytics. So a good data architecture will account for metrics that may not immediately seem important.
2. Build the data warehouse
Once the data architecture is designed, the next step is to build the data warehouse to the specification of the architecture. This part of the process is the main crux of building an ETL or data integration pipeline. In many cases, this is the only part of the data integration process that people think about: they tend to focus on building the integrations and transformations without first designing a robust architecture and, as a result, they end up with the unorganized, confusing data warehouses that I previously mentioned.
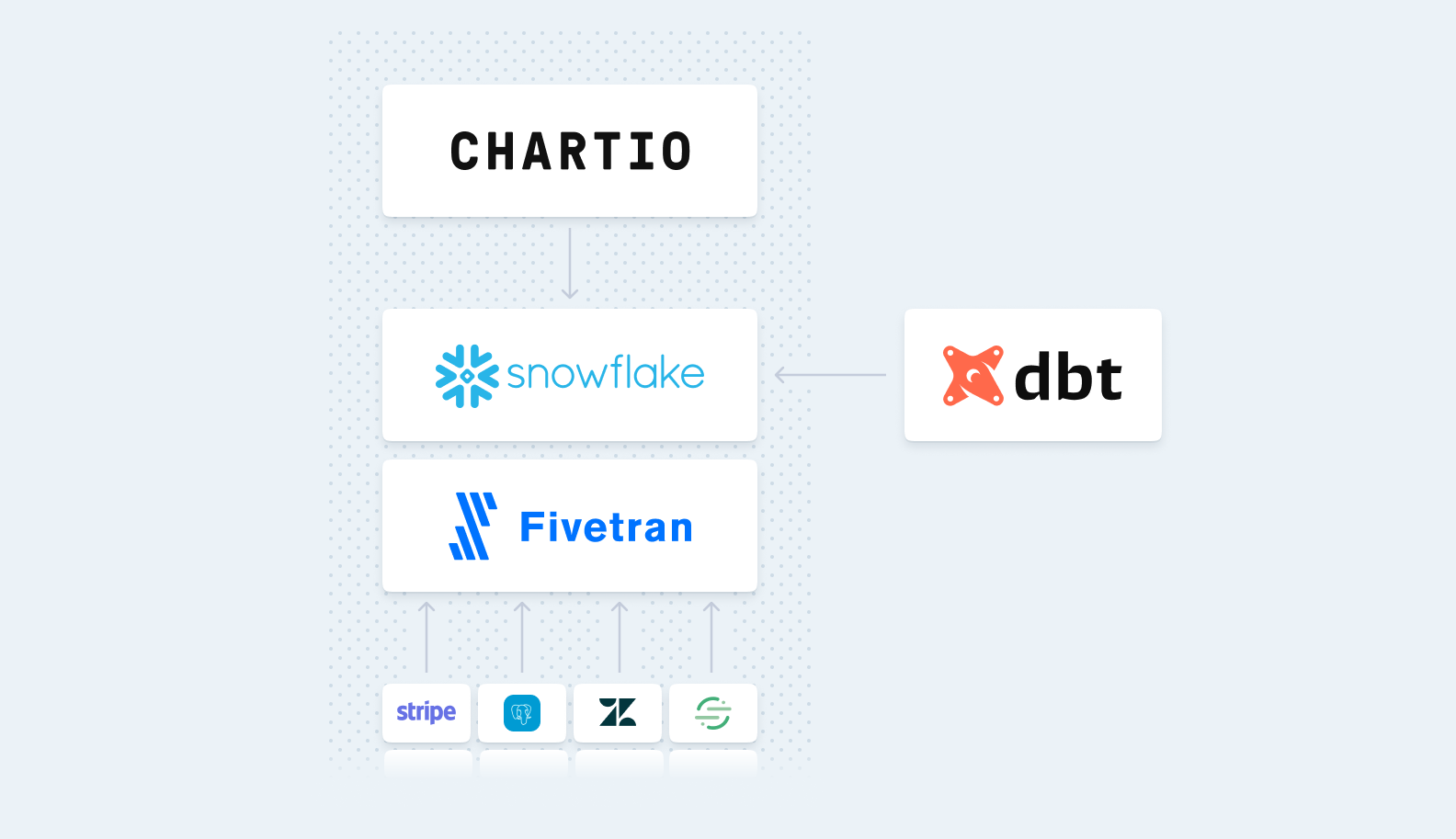
In this regard, it’s important to evaluate all possible options available to help with building the integrations and transformations or the process. A data integration platform like Xplenty is the perfect solution to help in this case. Xplenty is a cloud-based ETL platform that provides all the capabilities necessary to connect to a wide array of sources - including many different data warehouses - and perform all necessary transformations in between. In this regard, the painful part of ETL is abstracted from the user. Instead, the user can focus on implementing the data architecture and leave the headaches to Xplenty.
- Bring in a visualization tool:
Once the data warehouse is prepared and data is constantly flowing in, it’s time to bring in a visualization tool like Chartio. In these instances these tools are extremely effective, allowing users to query data sets and be confident that they are seeing all of the relevant data. Then, they can build queries that perform efficiently and gain valuable insight from the data. By keeping their data sets organized in this way, users can focus their time on building valuable insights rather than on wrangling with data sets.
Conclusion
In general, good hygiene leads to a better life. This is especially true when it comes to good data hygiene: if properly maintained, it can help you make sense of your data, organize your business efforts and gain key analytical insights that you can use down the road.
In short, it is the key to success in this growing world of big data and business analytics. Get started practicing good data hygiene today.
This guest blog post was written by Ben Perlmutter, Solutions Architect at Xplenty. Xplenty’s data integration platform streamlines data processing, reducing time spent and allowing businesses to focus on insight over preparation. Thanks to Ben and Etai Coles at Xplenty.