As data passes through a data pipeline, it is certain that there will need to be a place to store the results of that data processing. While it might be possible to simply perform every data operation from the original data sources, this is a wasteful approach. If a daily summary of activities needs to be performed, then without an intervening data store, there will be a lot of repeated effort from computing summaries not just from the most recent day, but from all previous days as well.
In addition, the final products of an analysis may not be the only points of interest. While a company might want to know about the amount of weekly sales as a top-level measure of performance, it’s likely that they will also want to know the breakdown of those sales by additional dimensions, through the volume of traffic, or demographics like region, age, or gender. Storing intermediate data values like this can allow for data to be used in different ways by different teams of interest.
There are three main ways in which data storage in the data pipeline can be classified: data warehouses, data marts, and data lakes. This article will provide an overview of each level in the data storage hierarchy and how they can be used to utilize and draw insights from data.
Database: Fundamental Data Storage Form
Before discussing the main data storage systems, it is worth taking a little bit of time to overview the most common form in which those systems house information. The database is the basic building block for working with data in a scalable and efficient way. There are multiple ways of systematically organizing data, but the most conventional type of database is the relational database. In a relational database, the data is organized into a series of tables, not too unlike those you would see in a spreadsheet program. Each row of a table refers to a single observation or entity, and each column a feature of each entity. One of the things that makes a relational database different from spreadsheet tables is the way in which information is linked between tables.
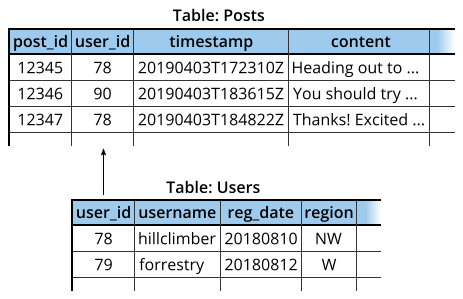
In the example above, the user information table is linked to the table of social media posts through the organizational structure of the database. By having the data stored in this way, information is also more consistent and less redundant than if the same data was stored in a single table.
 Note that the first and third rows have redundant information for a single user making multiple content posts.
Note that the first and third rows have redundant information for a single user making multiple content posts.
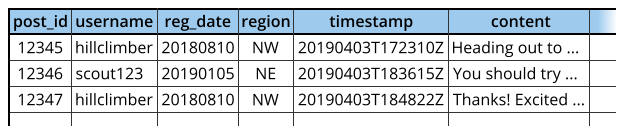
Information redundancy may be useful when it comes to the analysis stage, however (e.g. computing activity by user region). Database users can use queries through programming languages like SQL to join information across tables in a systematic fashion.
While most database systems that people regularly work with will be relational databases, there also exist non-relational databases for data that follow less structured forms. In a non-relational database, data points may not be held to a strict tabular schema. Certain points may have more or fewer features than others; there may be features that have multiple features themselves.
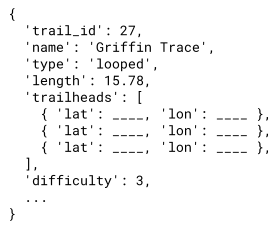 The example non-relational data point above contains a key, trailheads, with multiple values, each with multiple features themselves.
The example non-relational data point above contains a key, trailheads, with multiple values, each with multiple features themselves.
Data Warehouse: The Central Data Source
The data warehouse serves as the backbone of the data storage hierarchy in a data stack. It acts as a central store for all of the metrics and summaries that a company wants to track. While a data warehouse might consist of multiple databases, it is different from just storing all of the data from different data sources in a single place. Where an original data source might track all events within its specific domain, the data warehouse will summarize or transform that data, keeping only the parts that are relevant to analytic tasks. In addition, original data sources may only retain information for a limited period of time due to the amount of space raw data can take up. A data warehouse serves as a historical record of the key metrics so that changes over time can be clearly observed.
Another important consideration in having a data warehouse, and analytic data storage in general, is that there can be major differences between the databases required to serve customers and collect data, and the databases in a data warehouse that serve employees and facilitate data-driven insights. Databases that interact with customers often have to perform a large volume of queries with small scope, like pulling up product information or adding rows to a record of transactions. Systems that are built for these types of interactions are known as OLTP, for online transaction processing.
Databases that interact with employees have a different use profile. There will be much fewer queries on the system, but these queries will tend to be more complex, requiring the joining of data across multiple database tables and aggregation across many rows of data. While traditional OLTP systems can be used for analytic processing, this can start to become cumbersome with large amounts of data. Instead, OLAP systems, for online analytical processing, have been developed to handle the complex operations required for obtaining data insights.
Data Mart: A Focused Repository
If a data warehouse can be thought of as being analogous to a real life warehouse filled with goods and materials for creating any food dish, a data mart is analogous to a specialist retailer serving highly specialized products for a particular type of dish. A data mart is a specialized part of a data warehouse with contents tailored for a specific team, like sales, marketing, or finance. While all of these teams might be able to draw their information from a central data warehouse, a data mart has the advantage of being much easier to work with for everyday use. If a question comes up that a data mart cannot handle, then there is always the option of expanding the query to the data warehouse.
One other benefit of having a data mart is that it is easier to cordon off data access to different parties. You might limit access to the data warehouse to only a few people, while most people might only have access to a data mart relevant to their team.
Data Lake: Raw Materials for Deep Dives
Despite the fact that the data warehouse has been characterized as a central source for analytic information, it isn’t technically a complete source. As noted above, a data warehouse contains data summarized from one or more original data sources, serving metrics that a company wants to track. If new metrics need to be tested, then they will need to first be computed from those data sources before being added to the warehouse for analysis. This can result in a substantial delay in testing new ideas in order to schedule those transformations. When experimenting and exploring, it’s important to be able to iterate through ideas quickly.
The difficulty in accessing the complete data for new explorations is one of the motivating factors behind the use of a data lake. Data lakes are repositories of raw or only lightly-cleaned data that may not be directly applicable for analysis tasks. Data moved into a lake need not be structured or correspond to a standard database scheme. A data lake’s broad and flat structure means that it is possible for someone to perform as deep an investigation into the data as they would like, so long as the data exists. This can be useful if an interesting trend is initially observed from warehouse data, but the warehouse lacks a fuller amount of information that might explain that trend.
A question that might come to mind at this point is what makes a data lake different from just working from the raw data sources. One of the trickiest parts of working with data is accessing those original data sources. Each source might have different methods and permissions for access. It is much easier to just work with everything from a central repository, rather than having to juggle multiple data source connections at the same time.
However, just because data exists in a data lake does not necessarily mean that it will be easy to extract useful information from it. Increasing the amount and types of data that need to be processed means that even more different data storage solutions need to be employed. If a data lake is filled with information that is irrelevant or difficult to work with, then it can become a data swamp.
Summary
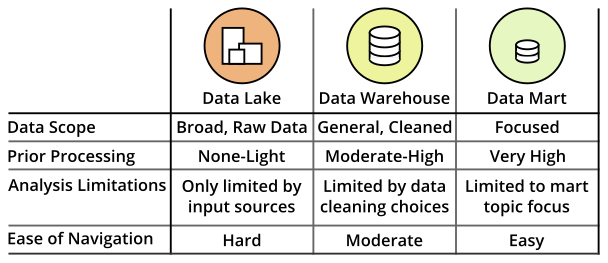
This article has outlined three major levels in the data storage hierarchy: data lakes, data warehouses, and data marts. Each has different tradeoffs in data scope and usability, as well as different needs for storage method and processing power. While most organizations will want to have a data warehouse to start off with, all three levels can be employed in a hierarchy to get the best of all worlds. While this can take multiple steps of data processing to put data into each of the different storage mediums, this can also allow users of all levels to access data that is relevant to the questions that they wish to answer.
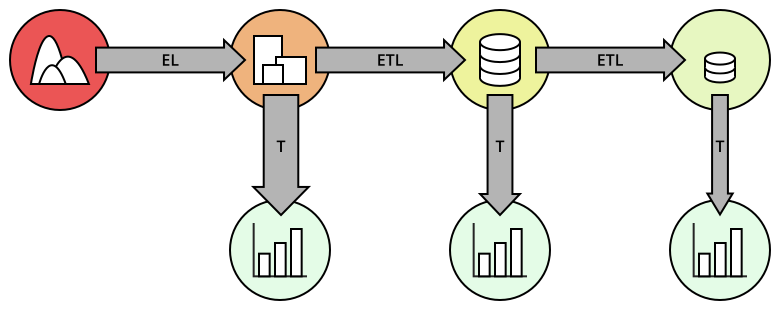 The letters found in the arrows stand for various processing steps in a data pipeline: see this article for more information.
The letters found in the arrows stand for various processing steps in a data pipeline: see this article for more information.
However, not all organizations will need all of these levels in order to make effective use of data. It takes a lot of work and specialization to actually make use of data in a data lake, so it may not be a high priority to get set up and working. In addition, maintaining multiple data storage systems incurs higher monetary and logistical costs. When starting out, a data warehouse is likely to suffice. As the amount of metrics tracked increase and teams require specialized parts of the central warehouse, data marts can enter the mix. And when a data team becomes large enough, building a functional data lake can then become a plausible extension to a data pipeline.
As a final note, it is worth noting that the line between data lakes and warehouses has blurred somewhat. Data warehouse capabilities have expanded greatly over the years, especially with managed cloud storage solutions like Amazon Redshift, Google BigQuery, and Snowflake. These cloud-based warehouses have a much higher storage capacity and better data processing power than traditional warehouses. Data stored in these warehouses will still need to be structured in nature, but they can be less summarized to facilitate a wider range of approaches.