Amazon Redshift: Taking Advantage of Parallelism
Posted by on November 6, 2014 Data, Data Analytics
In preparation for AWS Re:Invent, we’ll be posting weekly with our tips for optimizing queries, optimizing your Amazon Redshift schema and workload management. Download our Amazon Redshift white paper below.
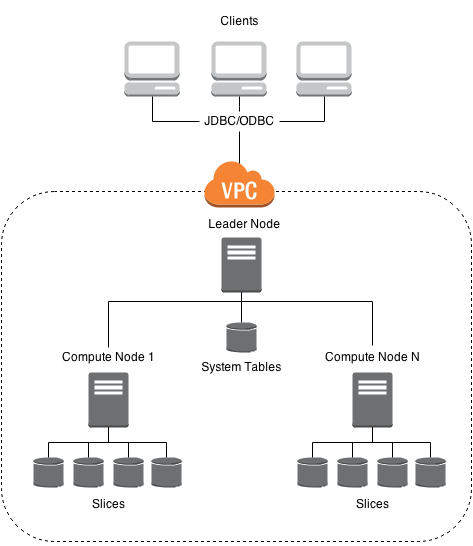
Amazon Redshift is commonly classified as a MPP (Massively Parallel Processing) or a shared nothing system. Aside from the single-node deployment option, an Amazon Redshift cluster is made up of a leader node and a number of compute nodes. The leader node is responsible for communicating with clients, parsing, rewriting and planning incoming queries and compiling code to be sent to the compute nodes for execution. The compute nodes are responsible for storing your data, executing the code sent to them by the leader node, and returning their intermediate result sets to the leader node.
Intermediate Results
What do we mean by intermediate result sets? No single compute node has a full view of the database - hence shared nothing. Each node’s disk is partitioned into slices based on the number of CPUcpu cores available (e.g. dw2.large nodes have 2 slices) and upon ingestion, your data is divvied up and distributed to these slices. Upon query, code received from the leader node is executed in parallel on each slice, and the results from each slice are sent back to the leader node to be sorted and merged into a final result set that is returned to the client. If you can fit your data set in memory, given the constraints of your budget, you will want to take advantage of this parallelism by optimizing for the number of slices when sizing your cluster.
Want to Learn More?
Download our white paper on optimizing query performance inside your Amazon Redshift cluster to learn more about optimizing queries with common best practices, designing your Amazon Redshift schema and defining query queues in workload management to increase performance and lower costs.